核心结论
流向清洗之所以是返利结算准确的前提,是因为返利所有计算、追溯和核销动作,最终都建立在流向数据是否真实、统一、可识别的基础上。
不少企业返利问题的典型表现是,公式没问题,规则也写清了,但每次结算仍然需要反复对账、反复解释,甚至不同团队拿同一批数据算出来的结果都不完全一样。
这说明问题通常不在“怎么算”,而在“用什么算”。如果底层流向数据本身不干净,那么再严谨的公式也只能建立在一个不稳定基础上。
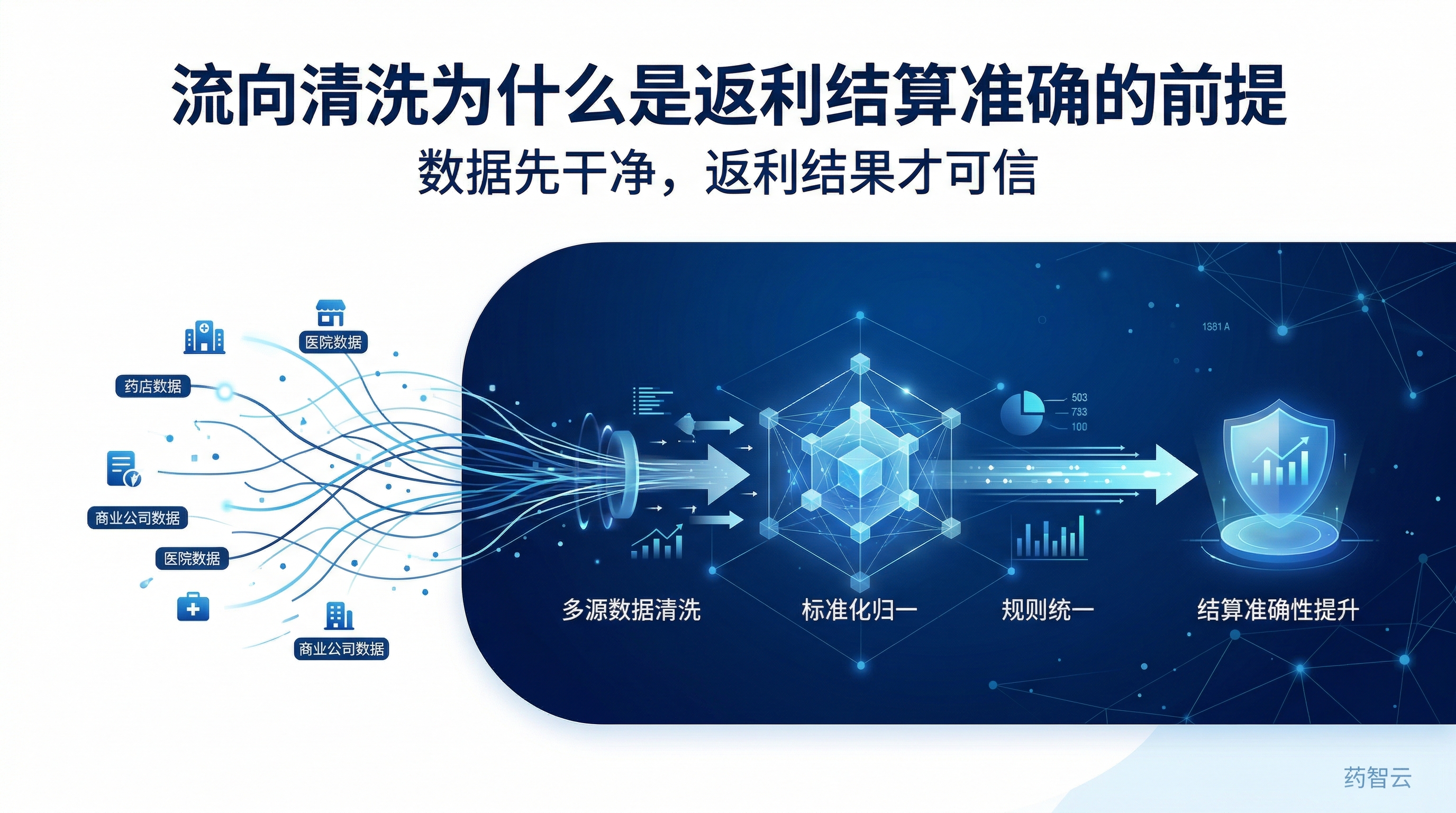
流向清洗具体在解决什么问题?
流向清洗看似是数据处理动作,实际上是在解决返利结算最底层的可信度问题。它至少在处理以下几类风险:
- 客户 / 渠道名称不统一
- 同一主体多种写法并存
- 时间口径和统计区间不一致
- 数据缺失、重复、错位
- 产品、区域、渠道维度归属不清
如果这些问题没有被解决,返利计算就会不断受到干扰。
常见误区:觉得清洗只是“技术预处理”
很多企业容易把流向清洗看成技术团队的前置工作,觉得只要差不多能用就行。但在返利场景里,清洗不是技术细节,而是管理基础。因为返利一旦不准,后面不仅是对账问题,还会影响渠道关系、费用核销、审计判断甚至业务信任。
企业该如何理解“先清洗,再结算”?
返利结算真正稳的企业,通常不是把结算团队做得多强,而是把前端数据治理做得足够扎实。更合理的理解顺序是:
- 先把多源流向数据收进来
- 再把名称、口径、时间、主体关系清洗和统一
- 然后基于稳定数据执行返利规则
- 最后实现追溯、核销和审计支撑
药智云如何承接这类问题
药智云在这类场景中的核心价值,不是单独优化返利结算动作,而是先通过流向清洗、AI 匹配和多源融合,把底层数据做稳,再让返利规则和结算动作真正跑在可信数据之上。
FAQ
为什么返利结算总是反复对账?
因为底层流向数据没有被统一治理,导致同一规则在不同数据基础上得出不同结果。
流向清洗和返利结算有什么关系?
流向清洗决定数据能不能被准确识别和统一理解,返利结算则建立在这个基础之上。
企业最容易低估什么?
最容易低估的是名称匹配、口径统一和时间校正这些基础动作对最终结算准确性的影响。
免责声明
本文仅供行业交流参考,不构成具体财务、审计或系统实施意见。